The Data Infrastructure for Next-Gen AI & Real-Time Computing
Building the Data Foundation for AI Agents with DolphinDB
Unified Multimodal Data Layer
One system for time-series, vector, and text — storing operational and semantic data together, eliminating the silos of multi-warehouse architectures. One codebase for feature training and real-time inference, with feature computation latency as low as microseconds.
Generative AI & LLM Ecosystem
MCP support connects LLMs directly to your enterprise data — query, compute, and generate strategies without leaving the data layer. Native vector search and Text-to-SQL make it fast to ship high-accuracy RAG pipelines and financial AI agents that reason on real data.
ML Inference Acceleration
Run model inference directly within the database — no cross-system data movement required. DolphinDB natively supports PyTorch, TensorFlow, XGBoost, and LightGBM, along with genetic programming and Monte Carlo algorithms, with GPU-accelerated parallel computing for significantly enhanced performance.
DolphinMind: RAG-Powered Enterprise AI Assistant
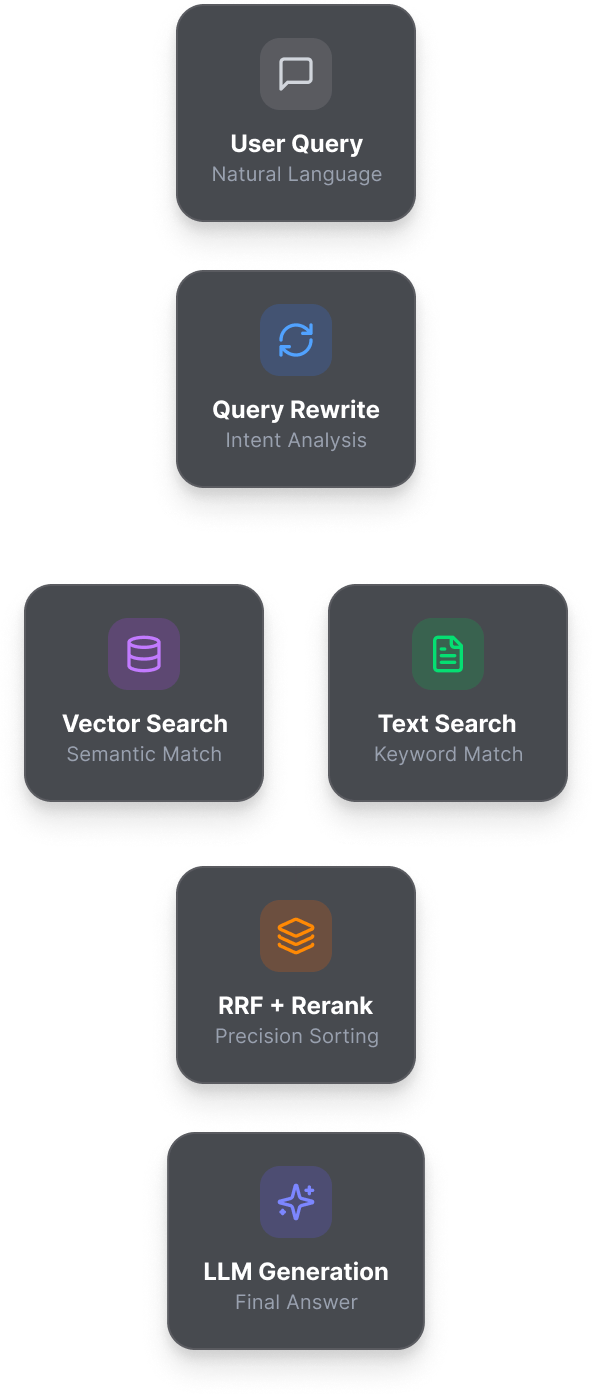
Built on DolphinDB's vector, text, and computing engine — DolphinMind answers technical questions about DolphinDB with speed, precision, and zero hallucination. Powered by a hybrid retrieval, multi-source retrieval, and reranking architecture that deeply integrates database and LLM capabilities.
Instant Response
DolphinDB's high-performance vector and text engine retrieves answers from massive knowledge bases in milliseconds — keeping every AI interaction fast and fluid.
Semantic + Lexical Retrieval
Hybrid retrieval understands complex semantic intent while precisely matching domain-specific terminology — ensuring every answer is grounded in evidence, with hallucination eliminated.
Deep Intent Understanding
Intelligent query rewriting and multi-source retrieval automatically expand context and extract key information from multiple dimensions — delivering precise, logically coherent answers.
Starfish AI: Intelligent Research & Factor Development
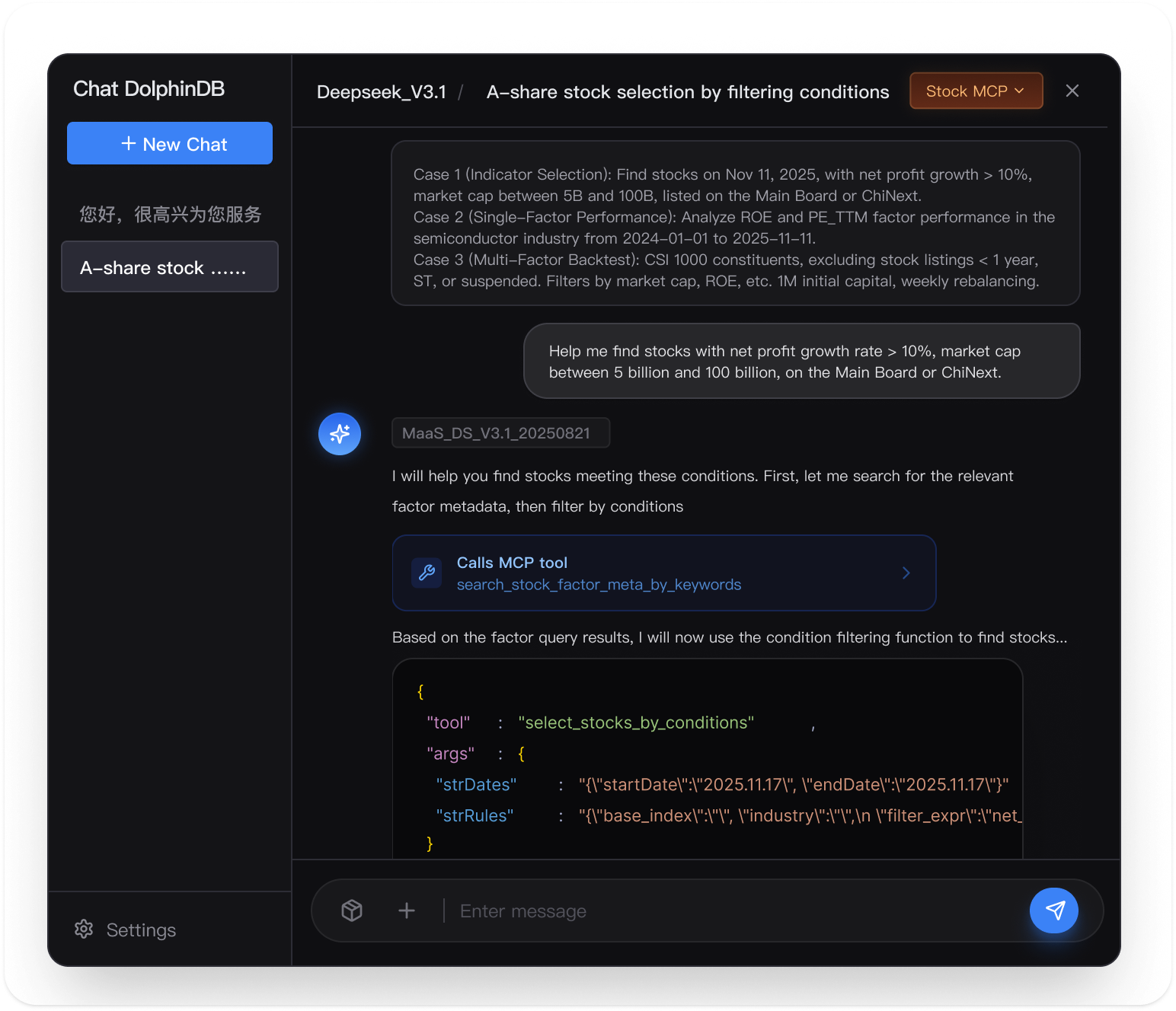
Starfish AI brings AI into every stage of quantitative research — from factor discovery to strategy execution — so your team spends less time coding and more time thinking.
Describe your factor logic in plain language. Starfish AI generates the code, runs the analysis, and surfaces insights across your full historical dataset — instantly.
Factor & Strategy Code Generation
From idea to executable script, ready for backtesting.
Natural Language Queries
Search across all tables, get results at scale, no SQL required.
Faster Iteration
Spend less time writing and debugging code, more time refining the logic.
Research Report Analysis
What Makes DolphinDB AI-Ready
Unified Vector & Time-Series Storage
Native time-series engine extended with vector and text indexing, storing time-series and semantic data in one system and eliminating cross-database migration latency for RAG and multimodal applications.
Stream & Batch Feature Engineering
One codebase for offline training and online inference. The built-in streaming engine handles both batch factor computation on historical data and millisecond-level factor computation on live streams, with the same logic ensuring a smooth transition from research to production.
GPU-Accelerated Computing
Switch seamlessly between CPU and GPU. GPU parallelism accelerates large-scale factor mining, cutting computation from hours to minutes.
Event-Driven Stream Processing
Multiple streaming engines trigger factor computation in real time, built for latency-sensitive applications.
Embedded Deep Learning Inference
Via the LibTorch plugin, trained models run directly inside the database kernel. Data in, prediction out — no external service calls, end-to-end inference latency reduced to the minimum.
Distributed Architecture with High Availability
Raft-based strong consistency and horizontal scaling support trillion-scale data throughput, with seamless failover built to financial-grade stability and security standards.
Your AI Applications